ARM(R) Cortex(R) Blog
Here you'll find miscellaneous observations, rantings and explanations concerning my work with Embedded Controllers of the ARM(R) Cortex(R) M family, the FreeRTOS operating system and Embedded development issues in general. This sort of supplements the book I wrote, but this'll be in English in order to reach a wider audience. Keep tuned in!
|
29. September 2018, 11:08 |
|||
Erratum: Code snippets in chapter 2 |
|||
|
Thanks to my reader Mr. Alexander Sido. He pointed out a copy-and-paste error in chapter 2.7.3 that has crept into the book during proofreading and apparently has gone unnoticed since. The assembly code fragments presented for optimization levels 1 and 2 are the same which of course should not be the case. The code generated with optimization -O1 should read as follows:
Entry: push {r4,r14} mov r4,r0 cmp r0,#01 bhi Cont add r0,r1,r0 pop {r4,r15} // Funktionsausstieg Cont: sub r0,r0,#00000002 bl Entry mov r1,r0 add r0,r4,#FFFFFFFF bl Entry pop {r4,r15} // Funktionsausstieg Apologies to all my readers and thanks again to Mr. Sido for pointing out the error. He will receive the promised token of appreciation soon. |
|||
|
|||
|
07. Oktober 2017, 15:05 |
|||
WinIdea Open back for good! |
|||
|
Hi there,
WinIdea Open will remain Online under the address pasted below. Thanks to iSystem for reconsidering their earlier decision! As it turns out, though, the iTag50 Debug Probe will bo longer be supported. That's not much of an issue, though, because ST Link and derivates will still be supported, and there are many many low budget ST Link clones available. |
|||
|
|||
|
30. August 2017, 21:11 |
|||
WinIdeaOpen temporarily back Online... |
|||
|
Hi everybody,
I have received confirmation from iSystem that pending further notice, WinIdea will remain Online here: http://www.isystem.com/download/winideaopen I'll keep you informed about changes in this matter. |
|||
|
|||
|
11. August 2017, 18:43 |
|||
WinIdea Open has disappeared!... |
|||
|
It has come to my attention that iSystem apparently discontinued Support for WinIdea Open. What's worse, they seem to have pulled every version released to this day from the Internet! What that means is that readers of my book may not be able to build and will definitely not be able to download and execute the samples unless they purchase a copy of the commerical release of WinIdea.
Needless to say, I'm shocked and outraged. I am in contact with iSystem and try to persuade them to at least keep a frozen release for download on the Web. In the meantime, I will rewrite all samples so that they build and can be debugged on another, more reliably available platform. If you have suggestions as to which IDE or toolset you can recommend, please let me know. Please accept my sincere apologies. There was no way to foresee this to happen. Fortunately, only a very small percentage of the book's content concern this particular IDE, so almost all of the discussions apply to most other tool sets as well. |
|||
|
|||
|
19. April 2017, 00:46 |
|||
lwip and concurrrent access to the same socket... |
|||
|
Hi everybody (which appears to be me, myself and I):
the sample accompaining chapter 7 of my book uses lwip as the network middleware. I've been using lwip in customer installations for years now, never experiencing any problems. However, in a recent private project (going to be published soon) I ran into spurious crashes and deadlocks. To make a long story short: I traced down the prob and got into contact with the chief developer of lwip. As it turns out, lwip (at least in version 1.4.1) does NOT support sharing a socket between tasks. In my sample, I have a dedicated task read from a socket and feed each character in turn into the protocol processing FSM, while output to the same socket all happens from within the tcpip_thread allocated by lwip. As it turns out, lwip is one of the platforms in which this architecture won't work. What WILL work is one thread/task does implements the protocol in a linear fashion (well, come to think of it, probably it won't work there either). I'll spare you the bloody tech details for now, but I'll follow up on the issue... |
|||
|
|||
|
12. April 2017, 17:33 |
|||
Code formatiing in the blog... |
|||
|
At this point, I need to apologize to you for the bad formatting of code in this blog. It's a shortcoming of the blog software supplied by my homepage provider. I'll look into the issue as soon as I can scram out a few cycles and reformat the code sections!
|
|||
|
|||
|
12. April 2017, 17:31 |
|||
Addendum on Software Watch Dogs! |
|||
|
In chapter 8, I discuss Software Watch Dogs. Courtesy of Segger Microcontroller, I learned about a very natural way to simplify the code: Instead of having the monitor task variable decrement a timer and test on 0, it saves codes and footprint to have the retrigger code forward an expiration time stamp to a future time and have the monitor task check whether the time stamp lies in the past, like so (remaining functions unaffected):
// Diese Variablen kontrollieren das Watchdogverhalten. TickType_t g_TaskWatchdog; void SWWDNachtriggern(void) { g_TaskWatchdog = xTaskGetTickCount() + WDNACHTRIGGERINTERVALL; } // Diese Funktion muss periodisch aufgerufen werden, z.B. im Kontext eines // Betriebssystemtimers void SWWDUeberwachen(void) { // nichts machen, solange der watch dog nicht aktiviert wurde if (g_TaskWatchdog) { if (g_TaskWatchdog > xTaskGetTickCount()) // watch dog // abgelaufen! { SWWDExpired(); } } } Aside from saving ressources, this code has the additional charm that the expiration timer tends to be more precise than the one presented in the book because if the monitor task has a comparatively low priority, the decrement skews add up with each decrement due to starvation (thus possibly deferring the expiration recognition), whereas in this solution, the first time the monitor task does the test after an expiration, the SW WD fires. Of course, this code is still somehwat unsafe because it simply tests whether g_TaskWatchdog is not zero to determine whether the task watch dog is active. If code erratically overwrites the memory location with 0 (or something which corresponds to a time way past in the future), missing retriggers will not be recognized. To relieve this problem, you may want to tag the g_TaskWatchdog variable with a signature that is requires to always contain an ACTIVE or INACTIVE signature. To further safeguard the monitor, you may want to check whether the time stamp is plausible (ie lies in within a window around the current timestamp that corresponds with the watch dog timeout policy). Again, thanks to Segger for providing a pointer to that information. The Segger embOS has this architecture built in with the additional feature that software watch dogs in embOS may serve arbitrary many supervised task. The monitor task will time out the watch dog if any entry has an exptected past time stamp. Straightforward and simple code, but as the saying goes, simple code tends to be better than equivalent complex code as less code bears less error potential. |
|||
|
|||
|
05. April 2017, 09:05 |
|||
More advanced Cortex DWT Debugging |
|||
|
In Chapter 10 of my book, I explain how the DWT can be programmed manually to break into the debugger when a particular value is written to a particular memory location. For example, to break when the 32-bit value 0x641a6350 is written to memory location 0x20001f88, use the following code:
// Komparator 4 Register, hier brauchen wir weder Maske noch Funktion
It goes without saying that the values of the comparator registers can also be determined dynamically at runtime. Let us assume for an example that we fault infrequently and found that every time this happens, a dynamically allocated variable contains an irregular value, such as this (code fragment of course): { unsigned char *a_Mem = (unsigned char *)malloc(xxx); if (a_Mem) { // do something with the memory .... // oops, sometimes we fault here and find that *a_Mem always // contains the wrong value 0x54 } }; Now apparently something (possibly a concurrent task or an interrupt handler) has overtrampled the memory allocate by a_Mem. Since a_Mem is not a static address, we can't use the above code verbatim, but of course we can program the DWT as soon as we know the value: { unsigned char *a_Mem = (unsigned char *)malloc(xxx); if (a_Mem) { *((unsigned long *)0xe0001050) = a_Mem; *((unsigned long *)0xe0001030) = 0x54; // use 0x3306 instead of 0x3b06 to match on an 8 bit write *((unsigned long *)0xe0001038) = 0x3306; // do something with the memory .... // Now the Cortex kernel will break into the debugger as soon as // the illegal value is written, and we know who did it! } }; |
|||
|
|||
|
18. Februar 2017, 16:42 |
|||
Erratum to Book Sample code... :-( |
|||
|
When reviewing the hostcomm sample, I discoverd a very stupid glitch in my code: In inc
cp_frame.h, you'll find the following line near the top: #define CP_MAXSHORTBUFLEN (CP_FRAMESTART+1) // test which is an unnoticed leftover from early experimentation. Of course there is no logical correspondence between the buffer len and the framing character; it simply works coincidentally. It should read something meaningful such as #define CP_MAXSHORTBUFLEN (0x40) or whatever makes sense in the sample's context. My apologies for this oversight! I truly hope that this is the last error in my code (though I don't hold my breath... we all know how it works...) If you should stumble across anything funny in the book or the accompanying sample code suite, please let me know! The first five successful bug hunters will receive a thank-you gift of my choice! |
|||
|
|||
|
04. Februar 2017, 15:07 |
|||
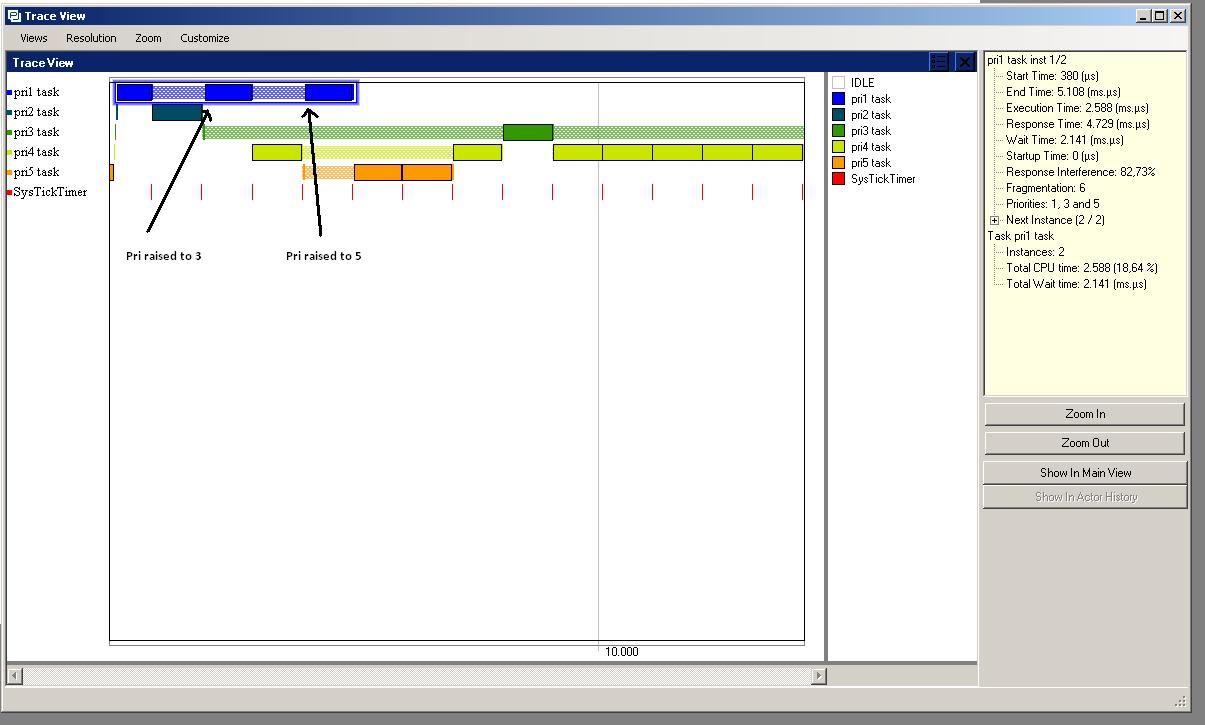
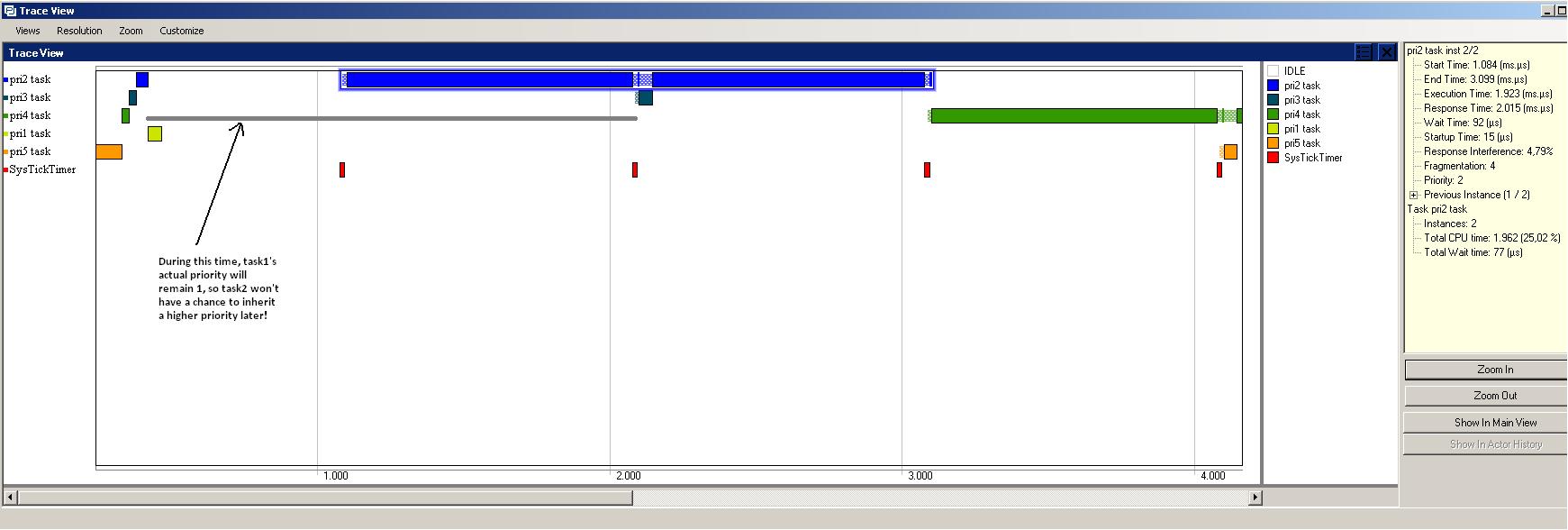
On priority inversion and priority inheritance |
|||
|
If you thought this entry to be useful, please leave a comment.
|
|||
|
|||
| Seite 1 von 2 |